車輪を最発明しようの会 リード・ソロモン符号
この記事は呉高専アドベントカレンダー2022 11日目の記事です。
ごあいさつ
こんにちは、点Nです。電気情報工学科卒です。高専在学中は高専プロコンに出たり、呉高専史上初めてICPC(大学対抗競プロ合戦)に参加して予選敗退したりといった感じです。
アドベントカレンダーというと「(最新の何かすごい技術)を使って(こんな面白いもの)作ってみた!」みたいな(勝手な)イメージを持っているのでそういうキラキラした記事を書きたいところですが、あいにくそういうのは性に合わないので黒い画面に白い文字が出るタイプのプログラミングをやります。タイトルにもある通り車輪の最発明をやりますので、みなさんは僕が車輪を最発明しているようすを見ていてください。目次の長さや画面右のスクロールバーの大きさから察している方も多いと思いますが、この記事はめちゃくちゃ長いです。せっかくの日曜日ですが(なので)、どうか最後までお付き合いください。
注意点
- 素人プログラミング
- ふわふわ理論
- ガタガタ構成
- エンドレス文章
それでもOKな人はどうぞ
はじめに
(呉高専アドベントカレンダーなので、高専を絡めた導入をどうにか考えました。)
高専といえばロボコン。世の中そういうイメージの人が大半ですが、高専にはそれ以外のコンテストもあります。代表的なところでは、ごあいさつで述べた高専プロコンというプログラミングの大会が有名です。その中の競技部門という部門では与えられた課題(対戦ゲームや一人用ゲームなど)を解くプログラムの強さを競います。しかしこの部門、稀に「プログラミングするより人間がやったほうが強い」という現象が起こることがあります。例えば、第23回有明大会の競技課題は「サイコロの山を見てその数を数える」というものでしたが、上位の成績を収めた多くのチームが(画像処理ではなく)人の目でサイコロを数えるという手段をとったそうです。
第27回鳥羽大会でも似たようなことが起きました。競技内容は木製のジグソーパズルが(現物で!)与えられるので解け、というものでした。パソコンにピースの形状を読み込ませ、正しい配置を探索するというのが正攻法なのですが、それでも解くのが難しく、また外枠内に収めたピースの数で評価したために「最大のピースを諦めて残りを人が急いで詰め込む」という計算機完全無視の手段がかなり強くなってしまいました。実際、翌年の募集要項に「昨年の大会では,手でパズルを並べると上位に来ることができました」という記述があります(https://www.procon.gr.jp/wp-content/uploads/2017/04/8db30280f6638520be40ad86b4bf1b37.pdf)。
勘のいい人はお分かりかと思いますが、募集要項にこのようなことが書かれた第28回大島大会の競技課題は、第27回の競技課題をアレンジしたものでした。競技者はペナルティを支払うことでパズルを解くヒントを利用することができるようになり、ヒントを使ってでも「パズルを完成させる」ことを重視する評価基準になりました。そして、ヒントは紙に印刷されたQRコードで配布されました。仕組みを理解していれば不可能ではないのですが、よほどの天才でない限りQRコードは人力では読めないので、さすがにプログラミングをせざるを得ません。
高専プロコンの話はこれぐらいにして、本題に入ります。このQRコード、多少汚れるなどしていても読み取れるのをご存知でしょうか。これは本来のデータだけでなく、いっしょに「データが壊れた時に気付いて、元に戻すための手がかり」も記録しておくことにより、汚れなどで欠けた部分を補って正しいデータを復元できるようにしているためです。
これを実現するための具体的なやり方はいろいろありますが、QRコードではリード・ソロモン符号というものを用いています。今回はこの符号を最発明します。といっても理論を思いつくのは不可能なので、意図的に壊したデータを頑張って復旧させるプログラムを書きたいと思います。
余談:人力という戦略について
人の力に頼ること自体は悪いことではありません。人もシステムの一部とみなして有効に使うことで非常に優れた問題解決能力を実現できる場合があります。例えば、第30回都城大会の競技課題は陣取りゲーム形式の通信対戦ゲームでした。1ターンの時間は数秒から十数秒と短く、人力で最大8人もの味方の動きを制御するのは難しいため、基本的にはコンピュータが考えることになります。しかし、味方全員は不可能であっても、その中の一人か二人程度であれば、その動きを人が決定することが可能です。「シンプルな戦略に則ってコンピュータが個々の味方の行動を計算、人間は必要があればそれを修正し、大局的に見てより良い手を柔軟に選択できるようにする」という方針をとった東京高専はこの年の競技部門で優勝しました(というかこの年は東京高専が3部門全てで優勝したのですが)。
当時の東京高専の学生によるツイート:
shibh308 on Twitter: "#procon30 深夜になってしまいましたが、東京高専競技部門の方針について説明します" / Twitter
計算能力ではパソコンに遥かに劣りますが、人の力も決して弱くはありません。問題を人力で解くことが十分強いのであればそれも立派な戦略だと思います。プログラミングの大会としてコンピュータを一切使わないのが最適ってのはいかがなものかと思いますが。
ふんわり理解するリード・ソロモン符号
リード・ソロモン符号(Reed-Solomon Coding, RS符号)はリードさんとソロモンさんが考えた誤り訂正符号(データにくっつけておくことでデータに発生した間違いを発見し、直せる符号)です。QRコードをはじめ、Blu-rayディスク、地デジ放送、ADSLその他諸々に応用されています。この世界はリード・ソロモン符号なしには成り立たないと言っても過言ではありません。ちなみに背景にある数学的な理論はちゃんと難しいです。
符号化・復号の流れ
いったん、細かい話は抜きでざっくり書きます。かなり説明不足で厳密性に欠けます。
符号化
線形代数の気持ちになります。小文字がベクトルで大文字が行列です。まず元の情報があります。これに生成行列
をかけて符号化します。それを
とします。
です。
は
よりちょっと長くなります。
は壊れるとおしまいですが、これを多少壊れてもいい符号語
に変換しました。終わりです。
復号
壊れている可能性のある、と思しきデータ
を
に復元しましょう。まず、
が本当に壊れているか確認します。これには検査行列
を使います。
とします。
はシンドロームと呼ばれます。
ならデータが壊れています。
の場合を考えます。これは混入したエラー
があって、
な状態です。
を復元するために
を特定します。方程式
を解けば
が特定できます(ざっくり過ぎてこの辺まではだいたいの実用的な符号化に当てはまる話です)。ですが、今は未知の変数が多すぎて解けません。そこで、先にエラーのある場所を調べ、エラーでないと分かった変数を消します。
そのために、からシンドローム行列
なるものを作ります。なんと
がエラーの個数です。さらに、
から誤り訂正多項式
を得ます。その根(
となる解)は
のどこが
と異なるかを示します。無事エラーの位置が分かりました。変数が減ったので方程式が解け、
がわかります。
から
を除去し、
がわかります。
なる
を求めれば、復号完了です。
忙しくない人と僕のためのRS符号の理論
実装するだけなら理解しなくても大丈夫ですが、RS符号がなんなのか全く分かっていないのもまずいので、ここでRS符号とはつまり何なのかについて知っておきたいと思います。適宜飛ばしてください。僕の理解が足りないので、間違った記述も含まれていると思います。
そもそもRS符号は何がすごいのか
とにかく訂正能力が高いです(そのぶん処理はやや複雑です)。正しいかは素人なので判断できませんが、僕は「理論値じゃん」という印象を受けました。
まず、符号どうしの距離を考えます。符号の最小距離は、異なる符号どうしのハミング距離の最小値です(ハミング距離は違っている場所の数です。たとえば、"abcde"と"abcxy"という符号のハミング距離は2です)。距離の小さい、つまり似たような符号があると、ちょっとしたエラーが発生するだけでそれらを間違えてしまいそうです。なので、
はできるだけ大きくなるように符号化したい気持ちになります。この最小距離は符号の誤り訂正能力に直結し、最小距離
の符号が訂正できるのは
未満の誤りだけです。直感的には、もとの符号から出発して、他の符号とのちょうど中間のところまで来てしまうと、どこに帰ればよいかわからなくなってしまう、というイメージです。
しかし当然ながらはどこまでも大きくできるわけではありません。
文字を
文字に符号化する符号において、
は
以下になります。これをシングルトン限界と呼びます。
ここがすごいところなのですが、RS符号は、最小距離がシングルトン限界に等しい「最大距離分離符号」です。だから訂正能力が高いです。
RS符号は未満のエラーであれば訂正できます。言い換えれば、訂正できるエラーの最大数は
個です。
RS符号とは
ずばり、こういうものです。
を体
の異なる元とする.
に対し,
における次数が
より小さいすべての多項式の集合
を考える.リード・ソロモン符号 (RS)符号 (Reed-Solomon code)は,以下の符号語の全体からなる.
(ただし
)
(参考書籍[1] p.63, 定義 4.1.1)
長さのメッセージを長さ
の符号語に変換する話をしています。体とは(ざっくり言うと)四則演算ができる世界のことです。その世界における多項式のうち、次数が
未満のもの(例えば
なら
以上の項がないもの、
や
など)をひとつ用意します。また、その世界から
個の元(要素、≒数)を持ってきて、その多項式に代入していった結果を並べて
のような
次元ベクトルを作ります。これがひとつの符号語になります。考えうるすべての多項式に同じことをして得られる符号語の集合がRS符号ということです。
あるメッセージと対応する符号語の関係をざっくり言うと、符号語は「メッセージを多項式関数に置き換え、1から順に数を代入した結果の一覧」です。符号化はこの一覧表の作成をやるだけです。復号は結果一覧から多項式関数を特定する作業になります。多項式が違えば結果はある程度異なるものになるので、結果一覧に誤植があっても、少しなら問題ありません(誤り訂正)。
は素数のべき乗なら何でもよいのですが、実用上は
を2のべき乗、
、
とすることが多いです。
は体
の原始元です。今回は全体的にこれにならうこととし、
とします。ASCIIコードでは1bitが1文字に対応し、1bitは256種類の数が表現できるため、体の元と文字の対応付けも簡単です。
なぜ体が出てくるのか
なぜ文字をそのまま0から255までの整数だけの世界(256で割った余りの世界/mod 256の世界)で考えようとしないのかですが、それだと困ることがあります。加減算と乗算はよい(結果を256で割った余りに置き換えれば0~255の範囲に収め直せる)のですが、割り算が困ります。なんと割り算ができないことがあります(例えばmod 256の世界に2x=1を満たすxは存在しません、これはmod 非素数 の世界を考えた時に起こります)。この先で割り算を使うので、四則演算ができる体、特に要素が有限で閉じている(演算結果も必ずその体の要素な)もの(=有限体/ガロア体)の世界で考える必要があります。
原始元とは
体の元であって、の原始
乗根(=
乗してはじめて1になるもの)です。これにより、体の0以外の元は原始元
を用いて
の形で表せます。
RS符号の世界(ガロア体)について
は要素数が
個と有限で、四則演算について閉じている(演算結果もまた体の元)という性質をもつ体で、これをガロア体とか有限体と呼びます。
ガロア体の例
最も簡単なガロア体は、ずばり、1bitの世界、0と1の世界です。です。加算や乗算は整数の時とほぼ一緒ですが、2で割った余りを取ります。実際には、1+1=0であることだけが違いです。減算と除算もその逆を考えればよいです。注意すべきは0-1=1なことぐらいです。あと、この世界でもゼロ除算はダメです。
この加減算は排他的論理和(xor)という演算で、0どうし1どうしでは0に、0と1では1になります。プログラミング言語でもこの演算が(大抵)サポートされていて、(大抵)^という演算子を使います。
同様に、素数に対してガロア体
を作ることができます。加算と乗算は
で割った余りになります。
ガロア拡大体(今回扱う体の話)
ガロア体を拡大し、
の
次元ベクトルを元(全
個)とするガロア拡大体
を作ることができます。面倒なのでここからは
で進めます。
を拡大し、
を作ります。
次元ベクトルの要素を
上の
次多項式の係数だと思うことにします。
のような感じです。加算はベクトルの要素ごとに和をとればよいです。つまりはbitごとにxorを計算するということです。乗算は少し大変で、
は、
が多項式
に対応するとして、
に対応する元(
は
上の
次の既約な(=因数分解できない)多項式)とします。
(ここから今回のでの話になります)
は原始多項式という既約多項式で、この根(多項式に代入すると0となる解)は原始元
になり、体の元は0を除いて
のべき乗で表せます。
は原始多項式の根なので
です。多項式的には、乗算のmodをこの多項式にします。
です。
結局、こんな感じになります。
の元は
と
の合計256個です。
です。
における四則演算は以下のようになります。乗除算については上の性質を使います。
- 加算/減算:bitwise xor(排他的論理和)
- 乗算:
- 除算:
体の元とbit列、多項式は次の表のような対応をします。
| 元 | 対応するbit列 | 多項式としての解釈 |
|---|---|---|
| 00000000 | 0 | |
| 00000001 | 1 | |
| 00000010 | ||
| 00000100 | ||
| 00001000 | ||
| 10000000 | ||
| 00011101 | ||
| 00111010 | ||
符号化
前提を再掲します:
符号化は、長さのメッセージ
を
上の
次多項式
とみて、
とすればよいです。実際には、生成行列
をかけるという操作によって符号化します。
生成行列と検査行列
生成行列は
の行列で、これを用いてメッセージの符号化を行います。符号の定義より、
です。今回の場合は
ですので、
となります。DFT行列に似ています。というか実際フーリエ変換そのものっぽいです(参考[6])。
検査行列は
をみたす(線形独立な)行ベクトル
を
個並べた
の行列です。上の生成行列
に対応する検査行列は
です。
理由
実際に計算してみるとわかります。とします。
です。
より
なので、等比数列の和の公式より
ですが、分子の
に注目すると
であるため、
となります。
に誤りがなく
ならシンドロームは
になるはずですが、そうならない場合はエラーがあることになります。そのときのシンドロームはどうなっているかですが、あるエラー
があって
と表せるので、ここに検査行列をかけた値
になっています。
エラー検出:ピーターソン法
でした。これを解けば
が分かるのですが、
より未知数に対して方程式の数が足りません。これを何とかします。
復号のアイデアは以下の通りだそうです。正直僕はあまり理解できてないです。
であって,以下の条件を満たすものを決定することである.
(参考書籍[1], p.65)
本文中で使ってきたはそれぞれ
に対応しています。条件1より方程式が
個できますが、条件2,3より
の未知の係数はそれより多くなるので、このような多項式があることがいえます。
また、この方程式に関して次の定理が成り立ちます。
送信語が
で生成され,そして,誤りの個数が
より小さければ,
が成り立つ.
(参考書籍[1], p.65, 定理4.2.2)
なぜ?
参考書籍[1], p.65, 定理4.2.2の証明に基づく説明です。
恒等的にであることを示せばあとは単純な式変形で定理を導けるので、それを示します。
「送信語がで生成され」るとは、
ということです。条件1より
です。エラー個数は
以下です。ということは
のうち
個以上の要素がゼロなので、それらに関しては
が成立しています。これにより
は少なくとも
個の根をもつことになります。ところがこの多項式の次数は条件2,3より高々
で、それより多い
個の根をもっています。ということは、
です。
エラーの位置はの根の中にあります(
と書けます。エラー位置
が根でないと仮定した場合、
を代入すると
より
、仮定より
で
になってしまいます)。この性質から
は誤り位置多項式と呼ばれます。
以後の最大次数を
と表します。
さて、ここから復号までには何通りかの方法があります。ここではピーターソン法と呼ばれる方法を取り上げます。この方法ではまずエラー位置特定(の特定)を行い、次に
を求めます。
第一段階、エラー位置特定です。次の定理を用います。(が奇数であることを仮定しています。偶数なら
は
になります)
誤り位置多項式
の係数は,次の連立一次方程式の解である.
(参考書籍[1], p.72, 定理4.4.1)
本当に?
参考[1] pp.72-74の証明にもとづいて説明をします。
のみたす条件1から、次のような関係が成立します。
両辺に左から次の行列をかけると、(生成行列に検査行列をかけたのと同様の原理で)左辺第一項が消えます。
残った左辺第二項は、次のように変形できます。
あとは、
であることを確認します。行列を分解したことで計算が簡単になって、右辺の計算結果は
になることが確認できます。いっぽう、左辺についてはで計算したことを思い出すと、
であることから一致します。
証明は省きますが、がこの方程式の解ならば最初の方程式の解
も存在します。
がわかればその根を総当たりで求めることができ、誤り位置が判明します。
第二段階です。でした。エラーの数は
以下なので、
はそれらを残してあとは全部ゼロです。未知数が減ったので方程式を解くことができ、
が定まります。
最後に方程式を解いて、元の
が復元できます。
実装
さて、だいぶ理論の話が長くなりましたが、ここから実装していきます。実装してから理論を書いたので若干記号が違ったりします。
何をするか
ユーザの入力:ASCII文字列とデータ破壊数
プログラムから見た入力:、つまり破壊された
出力:もとのメッセージ
手抜きPoint
- 今回はエラーがひどすぎて復元できない場合を想定しません。めんどくさいし、復号できないことがわかっても嬉しくないし、直せるものがきちんと直せると分かればいいので。
- ヒントとして、元のメッセージの文字数は復号プログラムに教えます。固定長になるように分割したり付け足したりするか、特定の書式を用意したりすれば解決するのですが、そこは面白くない場所なので。
- 計算資源に関する制約はあまり意識しません。最良の方法であることよりも実装の手軽さなどを優先し、一般的な家庭用のパソコンで実行したときに即座に実行が完了する程度に動けばよいことにします。
入力
入力された一行のメッセージを
getline()で受け取ります。cinは空白で区切られてしまうので不便です。符号化したメッセージの長さを
とするため、メッセージ長
である必要があります。もっというと破壊したいので
がよいですが、ここではとりあえず200文字以内のメッセージなら受理ということにします。自分が使うプログラムなので基本的には性善説に基づいた実装ですが、いちおう長すぎる入力や空の入力は弾くようにします。僕の環境ではどうにかなるようですが、マルチバイト文字は入れないでほしいです。
ついでにの破壊文字数
も入力してもらいます。最大で
文字破壊できます。それより上の要求は撥ね退けます。わけの分からん入力に関しては、文字列をint型の整数に変換する関数
stoi()様の解釈を正義とします。エラーの場合は再入力です。データを破壊しないこと、つまりは許容します。
const string input = Input::getRangeString("Input the string (<="+to_string(maxK)+" letters)",1,maxK+1); const int K = input.size(); const int maxChange = (N-K)/2; const int change = Input::getRangeNum("Input the number of data to be corrupted (<="+to_string(maxChange)+")",0,maxChange+1);
Input::xxx
namespace Input{ bool inRange(const int n, const int l, const int r){ return l<=n&&n<r; } bool isRangeNumStr(const string& s, const int l, const int r){ int a; try{ a = stoi(s); } catch(...){ return false; } return inRange(a,l,r); } string getRangeString(const string& message, const int l, const int r){ string S; while(true){ cout << message << endl; getline(cin,S); if(inRange(S.size(),l,r)) return S; } } int getRangeNum(const string& message, const int l, const int r){ string numString; while(true){ cout << message << endl; getline(cin,numString); if(isRangeNumStr(numString,l,r)) return stoi(numString); } } }
拡大体
上の元を表す型を用意しましょう。これを構造体alphaとして定義します。中身は8bitならいいのでunsigned char型にします。signedにするとろくなことにならない(筆者は論理シフトと算術シフトの違いで痛い目を見たことがあります)のでunsignedです。ここに加減乗除を定義します。演算子オーバーロードというやつです。これにより(ソースコード上で)普通の整数と同様に扱うことができます。
配列A[256]を用意し、Aを参照することでが即座に求められるようにします。
のような対応にしておきます。プログラムを起動したときに初期化関数を呼ぶことにし、配列Aは初期化関数内部で漸化式的に求めます。
加減算はbitwise xorなので^演算子を用いてシンプルに書けます。
乗除算も頑張ればbit演算でできる気がしますが、簡単な方法でやります。まず、0が絡む場合は場合分けして個別に処理します。それ以外は肩の数字のmod 255での加減算になります。各元は自分がの何乗なのかをわかっている必要がありますが、これも初期化の際にカンペを作っておいてそれを参照することにしましょう。
struct alpha{ unsigned char v; alpha():v(0){} alpha(unsigned char a):v(a){} const alpha operator+ (const alpha& r) const{ return alpha(v^r.v); } const alpha operator- (const alpha& r) const{ return alpha(v^r.v); } const alpha operator* (const alpha& r) const{ if (*this==0 || r==0) return 0; int expL = revA[v], expR = revA[r.v]; return A[(expL+expR)%255]; } const alpha operator/ (const alpha& r) const{ assert(r!=0); if(*this==0) return 0; int expL = revA[v], expR = revA[r.v]; return A[(expL+255-expR)%255]; } static alpha pow(int x){ if(x<0) x+=((-x)/255+1)*255; return A[x%255]; } static array<alpha,256> A; static array<unsigned char,256> revA; static void initialize(){ A[255]=0; revA[0]=255; for(unsigned char i=0;i<8;i++){ A[i]=1u<<i; revA[A[i].v]=i; } for(unsigned char i=8;i<255;i++){ A[i]=A[i-4]+A[i-5]+A[i-6]+A[i-8]; revA[A[i].v]=i; } } }
あと、後々面倒なのでalphaのベクトルや行列、すなわちvector<alpha>やvector<vector<alpha>>は略記ができるようにしておきます。
using Vec = vector<alpha>; using Matrix = vector<vector<alpha>>;
符号化
生成行列
の行列です。これを用いてメッセージの符号化を行います。行列(2次元vector)を作るだけなのでプログラミング的な面白さはないです。
const Matrix G = RS::MatrixGen::Generate(K,N);
RS::MatrixGen::Generate
Matrix RS::MatrixGen::Generate(const int K, const int N){ Matrix G(K,Vec(N)); for(int k=0;k<K;k++) for(int n=0;n<N;n++) G[k][n] = alpha::pow(k*n); return G; }
符号語生成
を計算します。
です。行ベクトルと行列を受け取ってその積(行ベクトル)を返す関数を作り、それを呼び出してあげます。
const Vec message = RS::MatrixGen::message(K,input); const Vec word = Math::mul(message,G);
RS::MatrixGen::message, Math::mul
Vec RS::MatrixGen::message(const int K, const string& S){ assert((int)S.size()==K); Vec word(K); for(int i=0;i<K;i++) word[i] = S[i]; return word; } Vec Math::mul(const Vec& a, const Matrix& M){ int H = M.size(), W = M[0].size(); Vec res(W); for(int i=0;i<W;i++) res[i] = 0; for(int y=0;y<H;y++) for(int x=0;x<W;x++) res[x] += a[y]*M[y][x]; return res; }
データ破壊
の成分を指定の数だけランダムな別の値に書き換えた
を用意します。面倒なので書き換える場所と内容はプログラムが乱数で決定します。
const Vec brokenWord = RS::MatrixGen::errorMessage(word,change);
RS::MatrixGen::errorMessage
そうする意味は特にないのですが、アルゴリズムの癖として、連続した場所を破壊する傾向にあります(既に破損させた場所を再選択した場合に右方向で最も近い未破損データを壊すため)。
mt19937 mt(chrono::system_clock::to_time_t(chrono::system_clock::now())); uniform_int_distribution<int> distN(0,N); uniform_int_distribution<unsigned int> dist255(0,256); Vec RS::MatrixGen::errorMessage(const Vec& word, const int change){ Vec brokenWord(word); vector<bool> changeFlag(N,false); for(int i=0;i<change;i++){ int pos = distN(mt); while(changeFlag[pos]) pos=(pos+1)%N; changeFlag[pos] = true; alpha after; do{ after = dist255(mt); } while(after==brokenWord[pos]); brokenWord[pos] = after; } return brokenWord; }
符号語比較
人間が見てわかるようにここでと
の比較を行いたいと思います。
符号語表示
alpha型の中身はunsigned char型の変数ですが、文字としてそのまま出力することはできません(ASCIIが対応するのは0-127までなので範囲外になることがあり、かつ範囲内にも改行やヌル文字などの表示できない文字=制御文字がある)。unsigned charが扱う0~255の値を2桁の16進数(適宜0埋め)に変換して表示します。
表示
ostream& operator << (ostream& ost, const alpha& a){ return ost << hex << setw(2) << setfill('0') << (int)a.v << setfill(' ') << dec; } ostream& operator << (ostream& ost, const Vec& v){ for(auto itr=v.begin();itr!=v.end();itr++) ost << *itr; return ost; }
比較
上の要領で符号語を人に読める文字にできますが、ふたつの符号語を上下に並べて表示したとして、それを比較するのはおよそ人間のやることではありません。違っているところを目立たせるために、文字と背景の色を反転させます。coutで出力するとき、\033[7mを噛ませることで反転、\033[0m=\033[mで戻すことができます(参考:
もう一度基礎からC言語 第47回 特殊な画面制御~コンソール入出力関数とエスケープシーケンス エスケープシーケンスによる画面制御
)。
compare(word,brokenWord,"Original","Broken");
compare
せっかくなので符号語以外のvectorも対応できるようにしておきます。
template <typename T> void compare(const vector<T>& A, const vector<T>& B, const string& s1, const string& s2){ assert(A.size()==B.size()); const string flip = "\033[7m"; const string endFlip = "\033[m"; cout << endl; cout << "------compare------" << endl; int N = A.size(); vector<int> dif; cout << s1 << ':' << endl; cout << A << endl; cout << s2 << ':' << endl; for(int i=0;i<N;i++){ if(A[i]==B[i]) cout << B[i]; else{ dif.push_back(i); cout << flip << B[i] << endFlip; } } cout << endl; if(dif.empty()) cout << "No error." << endl; else cout << "Error at:" << dif << endl; cout << "-------------------" << endl << endl; }
検証
検査行列
誤り検出に使用します。転置した状態で使うので最初から転置した状態のの行列にします。式にしたがって生成するだけなので特にいうことはありません。
const Matrix H = RS::MatrixGen::Check(N,N-K);
RS::MatrixGen::Check
Matrix RS::MatrixGen::Check(const int N, const int NK){ Matrix H(N,Vec(NK)); for(int n=0;n<N;n++) for(int x=1;x<=NK;x++) H[n][x-1] = alpha::pow(n*x); return H; }
シンドローム
でシンドロームを計算します。符号語を生成したときと同じ要領なので同じ関数を使いまわします。結果が
の場合はそのままメッセージを復号、そうでない場合は復号の前にエラー処理を行います。
const Vec syndrome = Math::mul(brokenWord,H); Vec restoredWord(word); if(!Math::isZeroVec(syndrome)){ const vector<int> errorPos = RS::specifyError(maxChange,syndrome); restoredWord = RS::restoreWord(brokenWord,errorPos,H,syndrome); } else { cout << "Data is not broken." << endl; }
エラー処理
を解けば
がわかりますが、このままでは解けないので先に
から零の要素を除去し、未知の変数を減らします。
RS::specifyError
vector<int> RS::specifyError(const int maxChange, const Vec& syndrome){ Matrix S = RS::MatrixGen::Syndrome(maxChange,maxChange+1,syndrome); const int rnk = Math::gauss_jordan(S); const Vec sigma = MatrixGen::sigma(rnk,S); return RS::findErrorPos(sigma); }
シンドローム行列と誤り位置多項式
の
行列になります。生成行列や検査行列に比べると少しややこしいです。
RS::MatrixGen::Syndrome
Matrix RS::MatrixGen::Syndrome(const int H, const int W, const Vec& syndrome){ Matrix S(H,Vec(W)); for(int y=0;y<H;y++) for(int x=0;x<W;x++) S[y][x] = syndrome[y+x]; return S; }
に掃き出し法を使い、対角成分に
が
個並ぶように変形します(
const int rnk = Math::gauss_jordan(S);)。下の行はゼロになります。エラー個数
が特定できます。掃き出し法についてはもう少し後で。
掃き出し法を使った後のから誤り位置多項式
を得ます。
の
列目の成分上から
個が、
となります(
const Vec sigma = MatrixGen::sigma(rnk,S);)。
RS::MatrixGen::sigma
Vec RS::MatrixGen::sigma(const int rnk, const Matrix& S){ Vec sig(rnk+1); for(int y=0;y<rnk;y++) sig[y]=S[y][rnk]; sig[rnk] = 1; return sig; }
理論と言ってることが微妙に違いませんか
文献[4]を参考に、エラー個数と誤り位置多項式を一気に求める方法をとっています。
ここから適当なことを言うのですが、根を求めるだけなので、誤り位置多項式には適当な定数をかけてよく、最高次の係数を1にすることができます。その状態から変形すると掃き出し法に持っていける感じがしてきます。
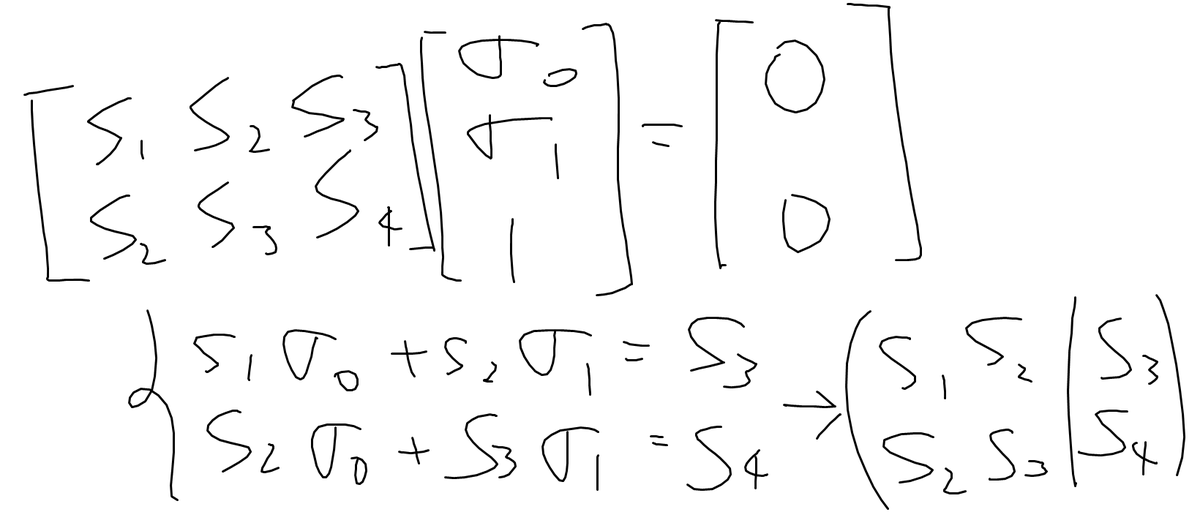
で、見つかるまで次数をあげていきながら多項式を求めている、という感じの処理になっている(のだと思っていますが、厳密な原理は参考元をあたってください)。
をみたす
を求めます。実際に
に元を代入して全探索で求めます(
RS::findErrorPos(sigma);)。
RS::findErrorPos
vector<int> RS::findErrorPos(const Vec& sigma){ vector<int> errorPos; for(int j=0;j<N;j++){ if(Math::polynomial(sigma,alpha::pow(j))==0) errorPos.push_back(j); } return errorPos; } alpha Math::polynomial(const Vec& coef, const alpha a){ alpha x(1), sum(0); for(const alpha& c:coef){ sum += c*x; x *= a; } return sum; }
今回は排除しているので心配いりませんが、一般にの場合、エラーが
個とは限りません(もっと多い可能性があります)。
の場合は、この後出てくる誤り位置多項式の根が見つからなくなるようです(参考:文献[4])。
掃き出し法
掃き出し法の実装がプログラム全体で最も難しいと思います。とはいっても、今回は誤差やオーバーフローの心配がなく、その点ではやや簡単ともいえます。基本的には人間がやるような感じをプログラムに書き直すだけです。
具体的な手続き
大まかな流れを記述します。行列に対して掃き出し法を行います。左の列から(
から)順番に、繰り返し処理していきます。
その列にゼロでない要素
をもつ(、固定されていない)行
をひとつ探し、
とします。
見つかったら、行
で割ります。
行
とし、各要素
に対して、
とします。
行
プログラムは雑に書くとそれ以降も参照する必要のある変数をうっかり書き換えてしまうバグを埋め込みやすいです。
Math::gauss_jordan
一部の処理の順番を入れ替えてあります。
int Math::gauss_jordan(Matrix& A){ const int H = A.size(), W = A[0].size(); int rnk=0; for(int x=0;x<W;x++){ for(int y=rnk;y<H;y++){ if(A[y][x]!=0){ if(y!=rnk){ swap(A[y],A[rnk]); y=rnk; } const alpha ayx = A[y][x]; for(int xx=0;xx<W;xx++){ A[y][xx] /= ayx; } for(int yy=0;yy<H;yy++){ if(yy==y) continue; const alpha f = A[yy][x]; for(int xx=0;xx<W;xx++){ A[yy][xx] -= A[y][xx]*f; } } rnk++; break; } } } return rnk; }
エラー除去
未知数が減ったので、方程式が解けるようになりました。
から必要な部分(
の非零要素、それとの掛け算が発生する
の行)を抜き出して、掃き出し法で方程式を解けば
がわかります。
として、破損前のデータ
を得ることができます。
RS::restoreWord
Vec RS::restoreWord(const Vec& brokenWord, const vector<int>& errorPos, const Matrix& H, const Vec& syndrome){ Matrix ErrorEquation = RS::MatrixGen::ErrorEq(errorPos,H,syndrome); Math::gauss_jordan(ErrorEquation); const Vec error = RS::MatrixGen::error(errorPos,ErrorEquation); return Math::sub(brokenWord,error); } Matrix RS::MatrixGen::ErrorEq(const vector<int>& errorPos, const Matrix& H, const Vec& syndrome){ int error = errorPos.size(); Matrix E(error+1,Vec(H[0].size())); for(int i=0;i<error;i++) E[i] = H[errorPos[i]]; E[error] = syndrome; return Math::transpose(E); } Vec RS::MatrixGen::error(const vector<int>& errorPos, const Matrix& E){ vector<alpha> err(N,0); int e = errorPos.size(); for(int i=0;i<e;i++) err[errorPos[i]] = E[i].back(); return err; }
メッセージ復号
遥か昔のことなので忘れそうですが、というふうに符号化したのでした。
はわかっているので連立方程式を解きます。これも掃き出し法で解けます。最後に復号したメッセージを出力して比較すれば無事
return 0;です。
const string output = RS::decode(G,restoredWord,K); cout << "Restored your input: " << output << endl; compare(vector<char>(input.begin(),input.end()),vector<char>(output.begin(),output.end()),"Original message","Recovered message"); return 0;
RS::decode
string RS::decode(const Matrix& G, const Vec& word, const int K){ Matrix Gw = Math::AugCoef(G,word); Math::gauss_jordan(Gw); string message = ""; for(int i=0;i<K;i++) message += Gw[i].back().toChar(); return message; }
ソースコード
全体実装はそれなりに長いのでリンクを貼ります。
動作確認
プログラムを動かしてみて、誤り訂正できていることを確かめました。僕の環境はC++14ですがC++11でも動くと思います。実行する場合は画面処理(文字色と背景色の交換)があるので対応できる環境で。Windowsのコマンドプロンプトではうまくいきません。どうにかできるとは思いますが、おとなしくPowerShellとかWSLを使ったほうが手っ取り早いと思います。

おわりに
リード・ソロモン符号(のおいしいところだけ、ですが)を実装してみました。何かの役に立つわけでもないし、画面に文字が並ぶだけで見栄えもしませんが、我々の生活を陰で支えるアルゴリズムに目を向けて、実装してみるのもけっこう面白いと思います。それでは。
XXXXXX_XXX_XXXXXXX_XX_XXX_XXXX_XXXXX
209be895e02f0bfdfc911a984fc51f516687cb55ce343c3c38b806c0a72b0a371f012706e6adc468c2a1ad20891f107d647b3b5935e9137aaace5db2fcd1164b9df34c3102c10dbd317af006ec43ea45e5c5c0ef28c7dfb606071457244d31c345a83df373d6aac8f0139b05bb84dd4aa3fb21c3742d5fe3dcefec442a1f01e2f5ba4d11f909ffe5ebdbfef722ad5fc15e0ed2160d5753ae08c9de9fa58ebd9c46fc8753d2cb5c92cf15f638d0796efddfd60b3fd89e5f6bdcc25940777b32343fdc677fa4bb98d42cefe74c18f15c190846f6fb32dd0489d296154aedd499c140936a8768e04470e70a5a0252413c6855df9604b895ccf44fee14fa103b5a
おまけ
当初は高専要素皆無だった導入部分(こっちのほうが自然でいいと思う)
情報は、時に欠落や破損をしてしまうものです。手の甲のメモが消えて読めなくなってしまったり、「ニンニク増しで」って言ったのに「ニンニク無し」が出てきたり、(この先は血で汚れていて読めない)
しかし、頑張ればなんとかなるケースも多々あります。なんか文字化けし縺ヲ繧けどギリギリ読める、誤字脱字がるけど陽はこういう意味だよな、と人間の脳は情報を補完します。
同じことをコンピュータの世界でもやっています。QRコードは多少汚れていても読めるし、ディスクに多少傷がついていてもCDは再生できます。必要なデータだけでなく、いっしょに「データが壊れた時に気付いて、元に戻すための手がかり」も記録しておくことで欠けた部分を補っているのです。
具体的なやり方はいろいろあり、その一つにリード・ソロモン符号というものがあります。今回はこれを最発明します。といっても理論を思いつくのは不可能なので、意図的に壊したデータを頑張って復旧させるプログラムを書きたいと思います。
参考文献
[1] 誤り訂正符号入門(第2版), イエルン・ユステセン, トム・ホーホルト原著, 阪田省二郎, 栗原正純, 松井一, 藤沢匡哉 訳, 森北出版(2019)
[2] 有限体(ガロア体)の基本的な話 | 高校数学の美しい物語
[3] 有限体でのガロア拡大(その3) - zuruyasumineko2002’s blog
[4] QRコードの符号化・復号アルゴリズム解説:学習読み物としての試み, 佐藤創, 専修大学情報科学研究所所報,76,37-52 (2011-06-30)
[5] Reed-Solomon符号を15分で理解する【M3 Tech Talk 第187回】 - YouTube
[6] リード・ソロモン符号とその復号法, 松嶋敏泰, 映像情報メディア学会誌 Vol. 70, No. 4, pp. 571~575(2016) https://www.jstage.jst.go.jp/article/itej/70/7/70_571/_pdf